标题:REPT: Reverse Debugging of Failures in Deployed Software
作者:Weidong Cui, Xinyang Ge, Baris Kasikci, Ben Niu, Upamanyu Sharma, Ruoyu Wang, Insu Yun
发表会议:USENIX OSDI 2018
原文链接:REPT Reverse Debugging of Failures in Deployed Software
Intro
众所周知,执行日志有助于调试,但当大多数日志或跟踪在正常运行时都会被丢弃时,没有人愿意为始终在线的日志记录/跟踪支付高性能开销。
因此,在部署的软件出现故障时,仅靠memory dump,以实现事后诊断。而开发人员调试memory dump具有挑战性,有很大一部分错误未得到修复
论文针对已部署软件中难以复现的故障诊断难题,提出了REPT系统,这是一种用于对已部署系统中的软件故障进行反向调试的实用解决方案。
REPT背后有两个关键思想
-
利用硬件跟踪以较低的性能开销记录程序的控制流。(Intel Processor Trace)
-
使用一种新颖的二进制分析技术,根据记录的控制流信息和存储在内存转储中的数据值来恢复数据流信息。(Offline Binary Analysis Component Loadable Library in WinDbg)
因此,REPT通过结合记录的控制流和恢复的数据流来实现反向调试。
Intel PT
由CPU内部集成的专用硬件实现。当程序运行时,PT硬件以压缩的格式生成一系列Packet,记录关键的控制流变化(分支跳转、函数调用等)
| instructions | PT | Decoded (timestamp, instruction) |
|---|---|---|
| mov | NT | 00.000000, mov |
| jnz | TIME 2ns + T | 00.000000, jnz |
| add | 0x407e1d8 | 00.000002, add |
| cmp | TIME 100ns + NT | 00.000002, cmp |
| je .label | 00.000002, je .label | |
| mov | 00.000102, call (edx) | |
| .label: | 00.000102, … | |
| call (edx) | 00.000102, test | |
| test | 00.000102, jb | |
| jb |
Linux Perf可以方便地收集和解码Intel PT跟踪数据
Design
如果指令I_x可逆,则可以从S_x推导出S_{x-1}
Instruction Reversal
⬆️ backward analysis
对于可逆指令的单个指令序列,由于每一条指令可逆,向后分析(执行反转后指令)即可
Irreversible Instruction Handling
⬇️ forward analysis
对于不可逆指令的单个指令序列,但指令序列不包含内存访问
|
|
排除掉访存(指外部数据源),那么数据的来源只能是寄存器或常量内存的地址(.text),而且它们的值是可用的。(简单的拓扑学)
而后者,可以从指令的hard-code操作数中取得
论文引入了向前分析(执行指令)以正确传播这些“常量”

给定指令序列I和结束状态Sn,首先将从S0到Sn-1的程序状态中的所有寄存器值标记为未知, After,进行向后分析以恢复从Sn-1到S0的程序状态。Then,我们执行正向分析以将程序状态从S0更新到Sn-1。Repeat, 直到在向后或向前分析中没有更新任何状态
当更新程序状态时,只会将寄存器的值从未知更改为推断值。此分析不会产生相互冲突的推断值,因为所有初始值都是正确的,并且分析中的任何步骤都不会基于正确的值引入错误的值。这也保证了迭代分析将收敛
Recovering Memory Writes
对于具有不可逆指令和内存访问的单个指令序列,
目标未知的内存写入指令,我们无法正确更新目标内存的值,而缺少更新则可能引入已经过时的值,若全标记未知则又会导致不必要且不可接受的信息丢失
err correction 解决问题的关键是引入纠错机制,可以利用有效值,去推断其他值,并在因产生冲突而无效时更新这些值

在向后分析的iter1中:由于不知道S4中rbx的值,我们不会更新[g];
在向前分析的iter2中:S3处的rax存在冲突,原始值3与新推断值4(rax+[g]=1+3=4),选择保留原始值3,因为它是从正确的最终态推断得来(可以理解为有一个类似置信度的比较)
在向后分析的iter3中:在S2处,根据I3前后rax的变化,将[g]恢复为2
Data Inference Graph
怎么做?
REPT在执行向后和向前分析时,会维护数据推理图,负责追踪数据值是如何向后或向前推断
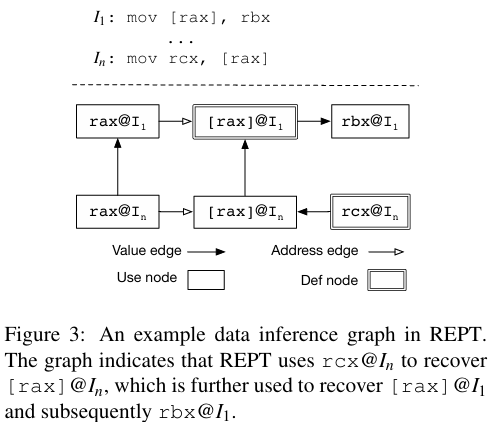
def node:写入节点,对应写入的寄存器或内存地址
use node:读入节点,对应读取的寄存器或内存地址
value edge:值边,AtoB,意味REPT用A值推断B值(rcx推断出[rax])
address edge:地址边,AtoB,意味REPT用A值计算B的地址(rax推断出[rax])
value edge
值边划分为两类:
- AB更新来自同一条指令,称为水平边。一个知可以具有多个水平边
|
|
- AB不属于同一条指令,但对应相同的寄存器或内存地址,称为垂直边。向后分析中,我们沿着def-use的节点方向,恢复之前的use节点或def节点。(简单概括就是,一个写入的值,若干时间后被读到。那么未来的use节点自然可以复原过去的def节点,当然路上的use节点也可以被复原)
Error Correction
值按向后、向前分析中传播时,会选取置信度更高的节点
REPT维护一个dereference level用于纠错。首先,memory dump中值的所有use node的ref lv为0
对于任何其他节点,计算其ref lv为:
- 对于所有传入值边的源节点的最大ref lv为D1
- 对于所有传入地址边的源节点的最大ref lv为D2
- D = Max(D1, D2 + 1)
每次解引用会使其中ref lv增加,这也意味着置信度降低(尽量减少可能导致数据推理错误的访问内存次数)
在不断更新迭代的过程中,新推断值与现有值不一致称为冲突,分为边冲突和值冲突
edge conflict:当一个确定的对应内存地址的写入节点的值不一致时,意味着不再是相同的内存地址。连接的垂直边会被破坏
value conflict:当一个推断值与现有值不匹配时,会根据减少访存次数原则选择置信度高的来源
更新失效的节点时,对于值边会沿着传出边将目标节点的值重写为未知,对于地址边会将目标节点从infer graph中删除。重复上述过程
同时,每个节点会记录已经失效的黑名单,以保证迭代过程最终是收敛的
Handling Concurrency
对于多核上同时执行的多条指令,论文使用Intel PT中记录的时序信息尝试还原不同线程的指令中的部分顺序,而内存写入是唯一其顺序可能影响内存恢复的操作
REPT会将多个指令序列划分为子序列,然后根据推断的顺序重新合并成一个新的指令序列(不能推断则使用任意一个顺序)
如果存在并发内存访问,那么考虑在垂直边的迭代中采用更保守的策略以限制可能错误的值传播(删除改内存地址节点的垂直边,以及连出的目标节点标记为失效。因为REPT不能推断实际值是并发写入之前还是之后)REPT仍保留水平边的推断
剩下的问题是,为并发指令子序列选择任意顺序是否会影响检测到同一位置的并发内存写入?
观察结论:只要没有两个单独的并发写入,一个写入会影响另一个目标值的推断,REPT的分析就有效。可能性存在,并取决于时序信息的粒度。鉴于现代硬件支持的时间戳粒度,论文作者认为这在实践中是一种罕见的情况
Evaluation
为了衡量REPT的有效性和效率,论文根据Chrome、Apache、PHP和Python等软件中的16个实际错误对其进行了评估
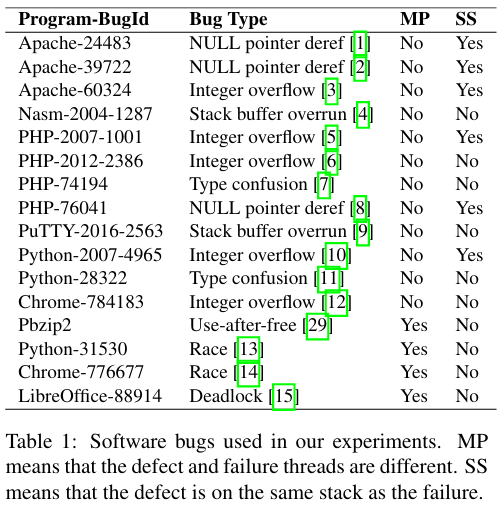
MP表示缺陷和故障线程不同,SS是同一堆栈上的缺陷和故障
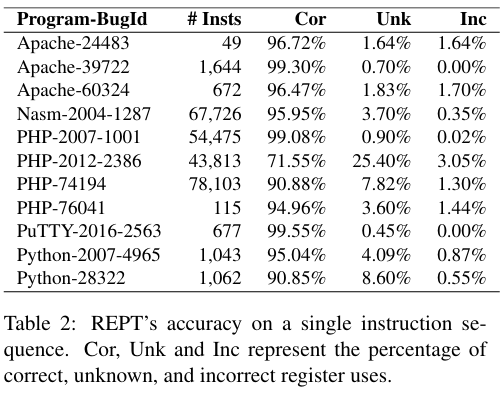
单指令序列上的准确性。Cor正确, Unk未知, Inc错误
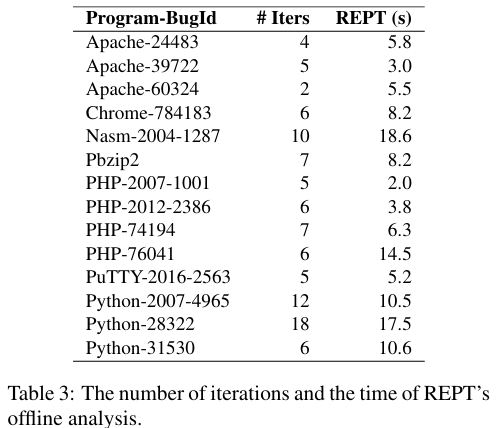
REPT离线分析的迭代次数和时间
实验表明,REPT可以对其中14个实现有效的反向调试,其中包括2个并发错误
通过将REPT的数据恢复值与Time Travel Debug记录的数据值进行比较来评估其数据恢复的准确性,REPT可以达到92%的平均准确率,并在不到20秒的时间内完成对这些错误的分析
Effectiveness
NotWork
Chrome-776677,因为于Chrome的V8引擎会进行实时(JIT)编译和动态代码更新,而Intel PT硬件是无感知地记录执行流。当已记录的代码区域被新代码覆盖,但Intel PT的Packet还指向旧地址时,解析器就会拿到错误的指令流,导致彻底混乱
LibreOffice-88914,因为这是一个死锁错误,触发了无限循环,填满循环跟踪缓冲区(Intel PT)并导致了在循环之前的程序执行历史丢失
Limits
- 控制流追踪长度不足以捕获缺陷
- Debug缺陷所必需的数据不能复原
REPT不会在程序执行时捕获所需的数据,而解决上述限制则需要记录更多数据而不是仅仅靠memory dump,so TODO(论文指出使用PTWRITE来记录有助于REPT复原数据的log)